Multimodal Deep Learning Violence Detector for Child-Friendly Online Game
DOI:
https://doi.org/10.17083/9k96e890Keywords:
multimodal, Deep Learning, child-friendly rated, Online Games, visual violence detection, verbal violence detectionAbstract
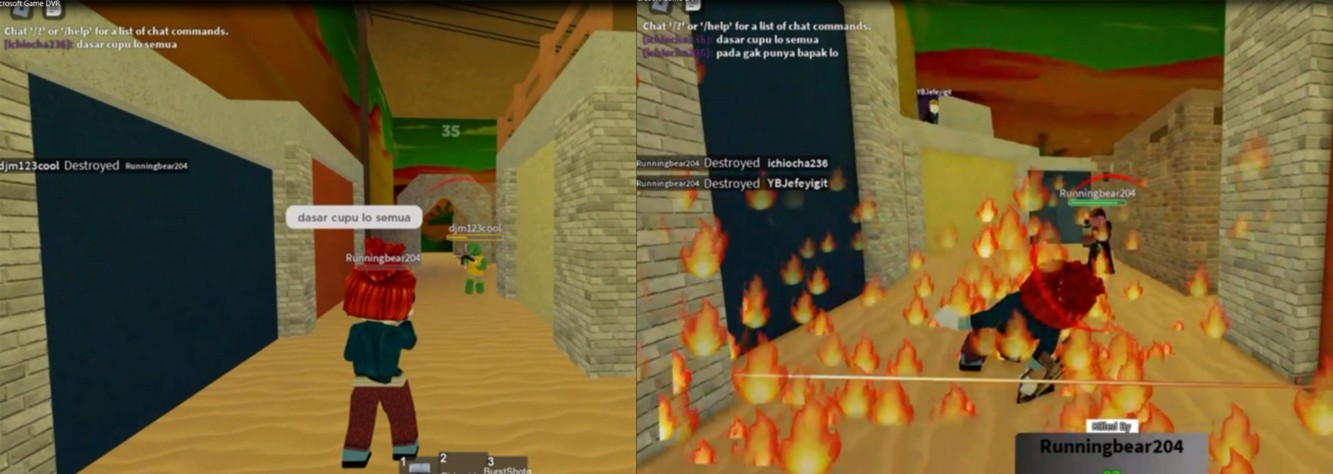
The violence present in child-friendly internet games includes both visual and verbal aggression. Visual violence occurs when players perform actions that harm themselves or another player's avatar. On the other hand, verbal aggression often happens during player interactions, even if no physical action takes place. This study explores whether a multimodal deep-learning framework can more effectively detect violence by simultaneously analyzing visual and verbal signals, and whether a hybrid late fusion approach provides better results than traditional fusion methods. Methodologically, the visual modality integrates 3DCNN, BiLSTM, and attention mechanisms, while the verbal modality incorporates BERT and BiLSTM. Each modality is handled independently. The hybrid late fusion employs rule-based and softmax probability to integrate the outcomes of each modality. The proposed multimodal model achieves an average accuracy of 96.72%, with 99.14% for the visual modality and 94.30% for the verbal modality. This performance clearly surpasses existing state-of-the-art fusion methods. The novelty of this study lies in the combination of each modality model and its integration of a hybrid late fusion multimodal approach. Additionally, the study outlines the process and stages for incorporating the model into a system suitable for any child-friendly online game, creating an early warning system for parents.
Downloads
Published
Issue
Section
License
Copyright (c) 2026 Jasson Prestiliano, Azhari Azhari, Arif Nurwidyantoro

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
IJSG copyright information is provided here.