Can ChatGPT Match the Experts? A Feedback Comparison for Serious Game Development
DOI:
https://doi.org/10.17083/ijsg.v11i2.744Keywords:
Game design, Serious games, Game-Based learning, Large language models, Artifical intelligence, ChatGPTAbstract
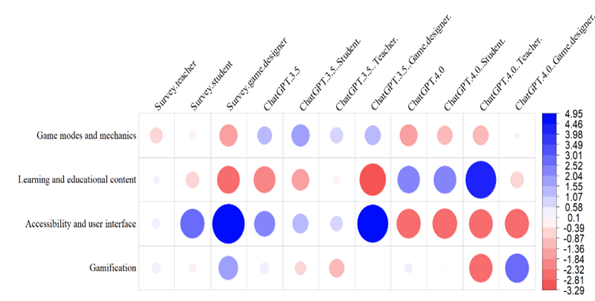
This paper investigates the potential and validity of ChatGPT as a tool to generate meaningful input for the serious game design process. Baseline input was collected from game designers, students and teachers via surveys, individual interviews and group discussions inspired by a description of a simple educational drilling game and its context of use. In these mixed methods experiments, two recent large language models (ChatGPT 3.5 and 4.0) were prompted with the same description to validate findings with expert participants. In addition, the impact on the models’ suggestions from integrating the expert’s role (e.g., "Answer as if you were a teacher.", "game designer", or a "student") into the prompt was investigated. The findings of these comparative analyses show that the input from both human expert participants and large language models can produce overlapping input in some expert groups. However, experts put emphasis on different categories of input and produce unique viewpoints. This research opens the discussion on the trustworthiness of large language model generated input for serious game development.
Downloads
Published
Issue
Section
License
Copyright (c) 2024 Janne Tyni, Aatu Turunen, Juho Kahila, Roman Bednarik, Matti Tedre

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
IJSG copyright information is provided here.